久其新合并报表提速“合并计算”——基于Fork/Join框架实践
合并计算是合并报表的“算力中心”,可以将各个业务模型采集的数据,根据抵销规则策略、数据先后关系等,进行自动识别和计算,生成抵销分录。随着企业集团财务报告精准合规的要求越来越高,且股权关系日趋复杂,数据抵销粒度越来越细,合并计算将面临更加复杂的抵销规则,以及更大的数据量级,对合并计算的实时计算能力提出了更高的要求。
挑战即是机遇,随着久其女娲平台技术底座在业务上的广泛应用,久其技术体系提升到一个新的高度,久其合并报表产品“合并计算”能力也在新一轮技术迭代中给出了新的解决方案。
上一代合并报表产品的“合并计算”能力遇到了什么瓶颈?
上一代产品“合并计算”使用的是普通线程池,但在一些超大型项目中,线程池存在以下问题:
父子任务问题:使用数量有限的线程来完成非常多的具有父子依赖关系的任务时,由于ThreadPoolExecutor中的Thread无法选择优先执行子任务,所以完成N个父子关系的任务时也需要N个线程,导致线程池中的线程使用效率不高。
并行处理问题:使用多个CPU核心并行处理时,比如在100个用户并发400个合并规则分治场景下,若每个线程所处理的规则数量过少则会存在大量的线程间的频繁资源竞争;若处理数量过多则会存在每个任务执行时间不一致的情况,从而导致整体任务时长往往取决于线程池的最懒线程的用时,造成整体任务进度被拉长。
为此,我们需要一个更高效的技术解决方案。在对比测评目前主流的进程内并发并行技术后,如ThreadPoolExecutor、Disruptor、CompletableFuture 、Fork/Join等,最终发现Fork/Join的分而治之、双端队列、工作窃取等特性能很好解决我们当下的问题。
 那么什么是Fork/Join?它具有哪些特性?如何应用在“合并计算”中的?请听小编慢慢道来。
那么什么是Fork/Join?它具有哪些特性?如何应用在“合并计算”中的?请听小编慢慢道来。
一、Fork/Join框架原理
在具体介绍Fork/Join之前我们先了解下单线程以及线程池的一些概念:
单线程
单线程处理多任务时,所有任务都得排队等待,逐个处理,这样任务吞吐和执行效率是非常有限的,特别是I/O阻塞的情况下会更明显。
线程池
普通线程池属于典型的生产者/消费者模式,消费者线程都从一个共享的 WorkQueue 中消费提交的任务,这种模式下,通常一个任务会分配给一条线程执行,而往往会导致一种情况:如果有个任务耗时比较长,并且在处理期间也没有新的任务到来,线程池中只有一条线程在处理这个大任务,而其他线程却空闲着。这会导致CPU负载不均衡,空闲的处理器无法帮助工作,从而无法最大程度上发挥多核机器的性能。
此时,如果能将这个大任务拆分成很多小任务分而治之的话,处理性能就会得到极大提升。因此, Fork/Join 作为功能补充就出现了。
二、 什么是Fork/Join
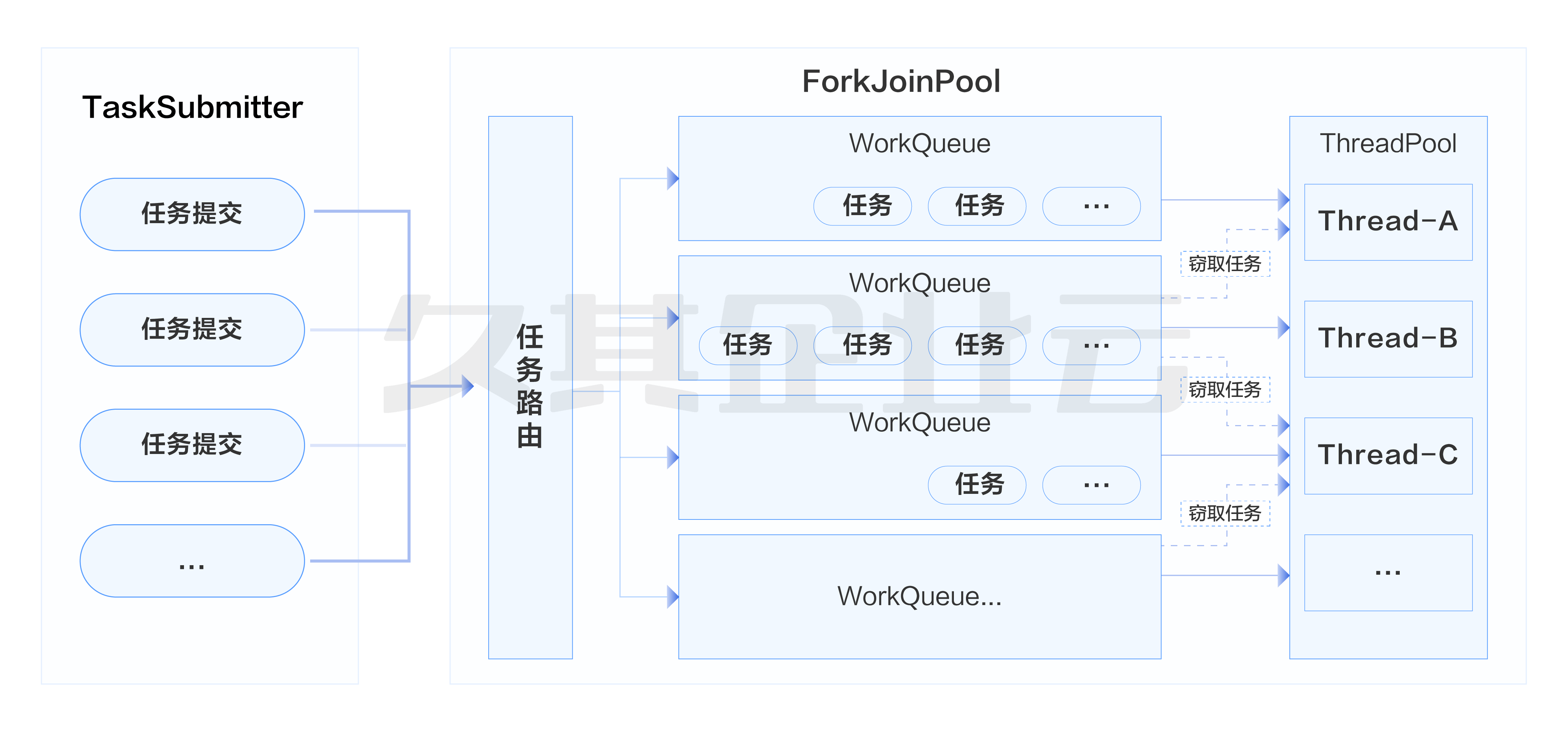
Fork/Join框架是从JDK1.7中引入的,它提供了ForkJoinPool线程池工具来实现进程内任务的分叉(fork)和合并(join)能力。 ForkJoinPool同样实现了多线程处理器,并提供了分而治之算法、工作窃取算法等特性,充分利用了CPU资源,提高了整体执行效率。
分而治之
Fork/Join是一个建立在分治思想上的产物,通过“大拆小”的方式,可以把一个大的任务划分为若干个小的任务并发处理,达到分而治之的功效。其分治思想类似于大数据处理框架MapReduce。
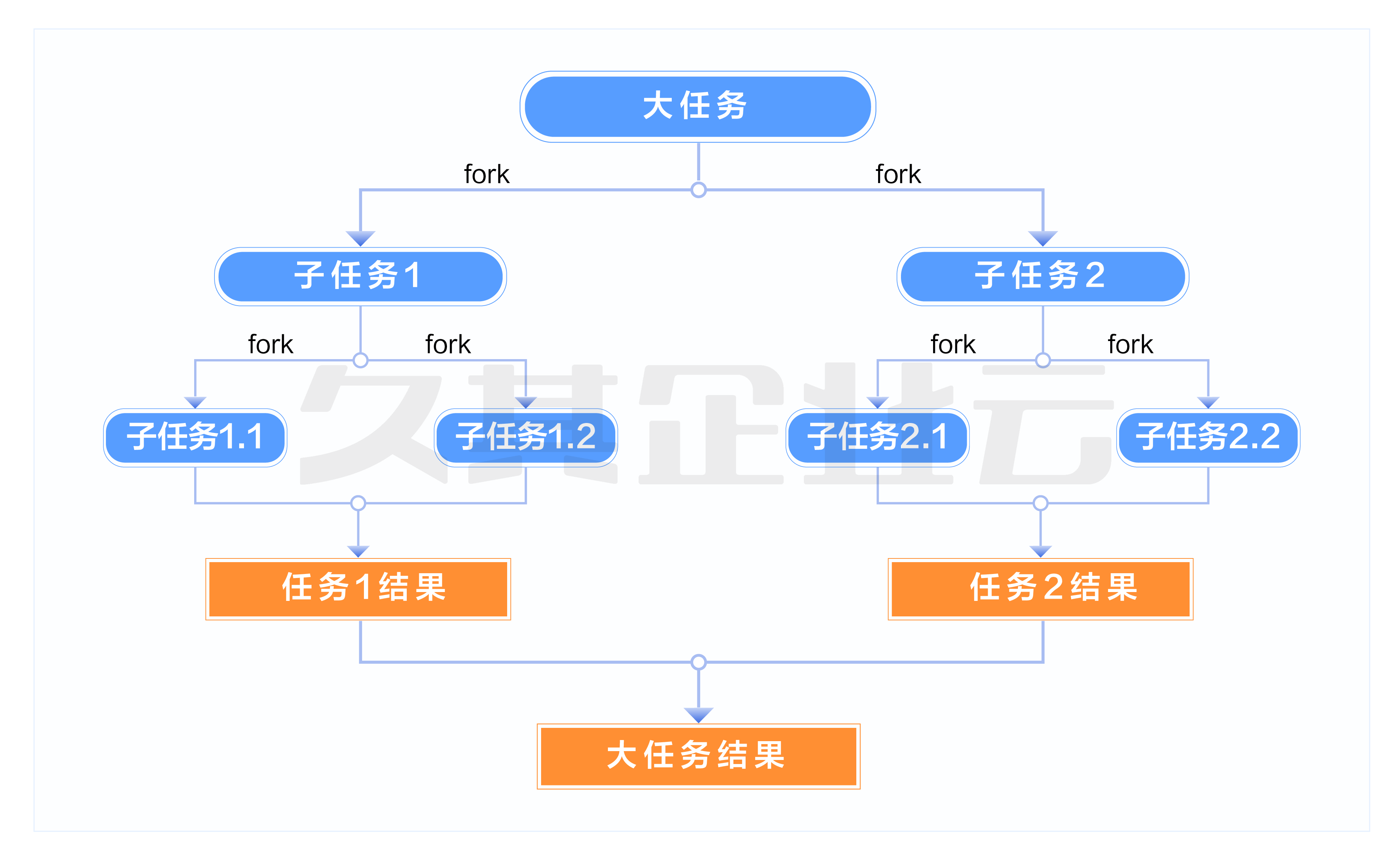
通俗来说,Fork/Join框架将大型复杂任务进行递归分解,直到任务小到指定阈值时才开始执行,从而递归的返回各个小任务的结果,汇集成一个大任务的结果,依此类推得到最初提交的那个大型复杂任务的执行结果。
工作窃取(work-stealing)算法
假如我们需要以较少的线程来完成一个较大的任务,我们可以把这个任务分割为若干互不依赖的子任务。为了减少线程间的竞争,需要把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如A线程负责处理A队列里的任务,B线程负责处理B队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。
干完活的线程与其等待不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行,而在这时它们会访问同一个队列,形成了竞争。因此,为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
总的来说,当任务能被分割成一个执行效率平衡的集合时,分割并使用ThreadPoolExecutor会得到更好的性能,反之则是ForkJoinPool更适合。然而,实际应用中往往都是执行效率不平衡的场景。
三、Fork/Join框架应用
下面以合并报表的合并计算业务场景,看看Fork/Join框架如何产生更高的效能。
合并计算业务背景
大型企业集团合并报表的编制,通常存在单位多、报表数据量大、编制周期长等情况。在编制合并报表时,通常是以企业集团为会计主体,以母公司和子公司单独编制的个别会计报表为基础,并由母公司编制出反映企业集团财务状况、经营成果及现金流量的会计报表。
为了满足企业快速出具合并报表的需求,通过“合并计算”环节,可以将母公司与子公司、子公司相互之间发生的内部交易数据,按照系统内置的合并抵销规则“一键生成”抵销分录,减少人工编制抵销分录的工作量,大大缩减合并报表的编制周期。
合并计算业务特性
合并抵销规则约12个大类,如:普通规则、固表规则、固定资产规则、存货规则、灵活规则、直接投资规则、间接投资规则、公允价值调整规则、浮动行规则、关联交易规则、租赁规则、凭证级关联交易规则。
项目实施合并抵销规则约400个明细条目。合并抵销规则大类之间存在时序优先级依赖约束,如:投资规则/分段投资规则需要依赖等待普通规则/存货规则这种非特殊类合并规则处理完毕后的结果再计算。
合并计算方案设计考量
同维度下的合并计算任务需要保证同时只允许一个用户执行。
合并计算任务进度在集群环境下需要提供分布式进度信息。
合并抵销规则明细条目较多,需要实现大任务拆分小任务工作机制来提升效率。
合并抵销规则之间存在运算依赖,且大部分规则的运算需要公共的上下文,为了避免不必要的冗余清洗工作,合并计算优先采用了集群内计算的策略。
针对每个合并抵销规则做独立的事务处理。
合并计算方案落地
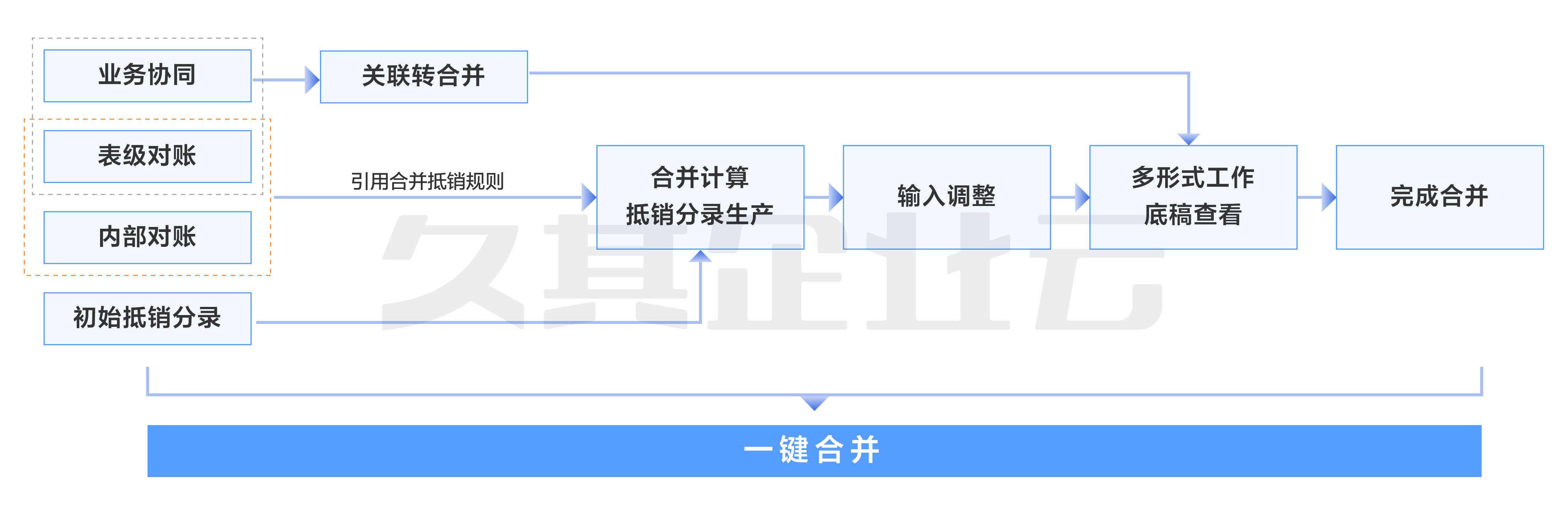
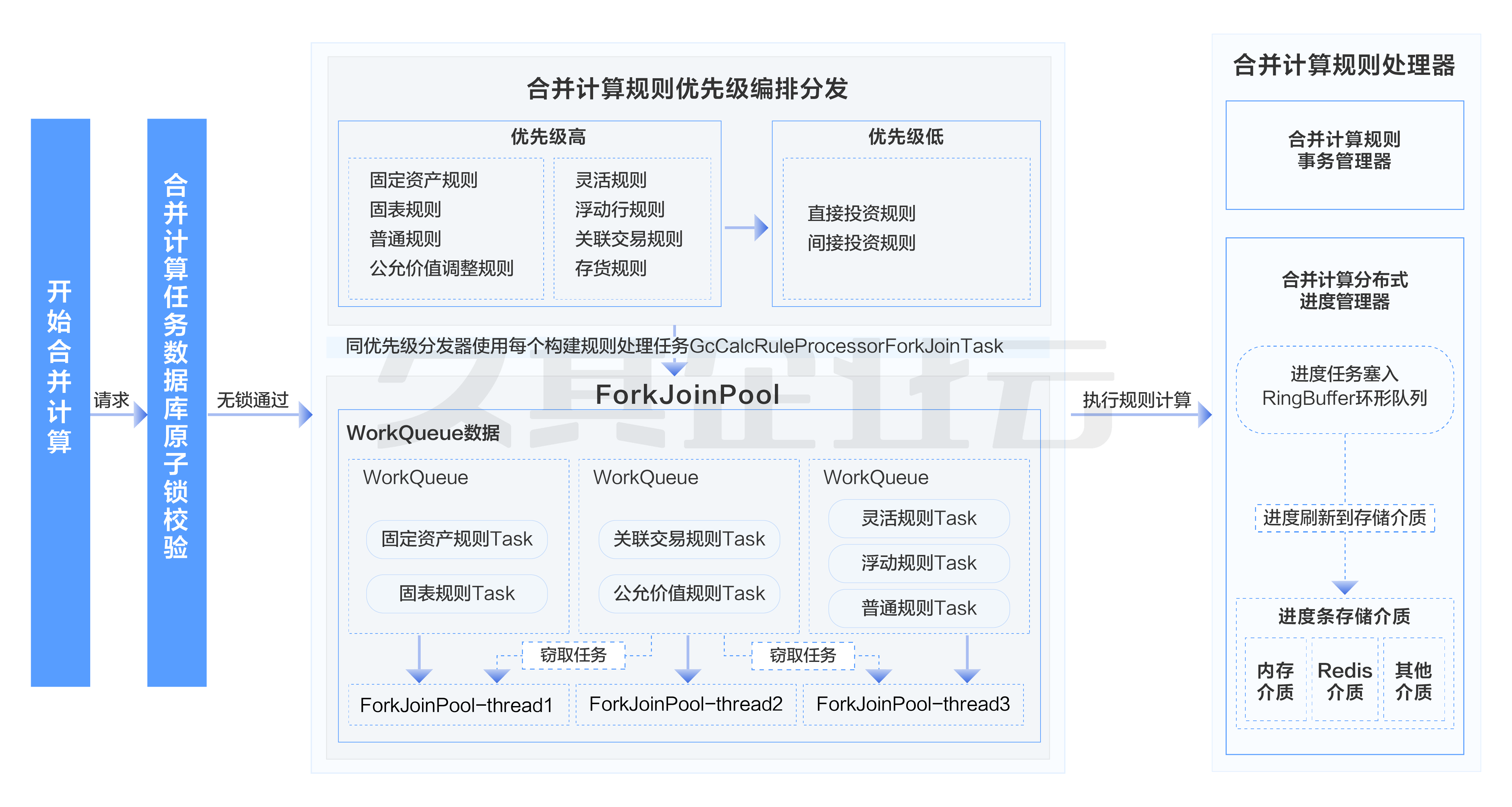
合并场景下在某个单位选择全部规则开始合并计算时,整体处理流程如下:
采用以报表任务、报表方案、币种、时期、合并单位类型、合并单位等组合维度作为键来定义分布式锁,保证在多个用户对同一合并单位进行合并计算的场景下只允许一个用户在执行。
合并计算会执行一大批合并规则,规则分为很多类型,有些规则需要依赖其他规则运算完毕后的结果再做运算,将合并规则按不同大类归纳到规则分组,并编排规则分组处理任务的优先级。其中将普通规则、固表规则、固定资产规则、存货规则、灵活规则、浮动行规则、关联交易规则、租赁规则、凭证级关联交易规则划分为优先级高的分组,将直接投资规则、间接投资规则划分为优先级低的分组。
针对相同优先级分组下的所有合并规则,为了提升效率,合并计算会将这一批合并规则作为一个大任务丢入Fork/Join中,然后Fork/Join会按设定的每一个规则为阈值自动拆分成N个小任务并行运算生成对应规则下的抵销分录。比如:在投资类规则依赖同一批投资台账数据生成抵销分录的场景下,合并计算会将直接投资规则、间接投资规则组装到同一个分组下,并组织好满足条件的投资台账数据作为分组下的公共上下文,然后分组和组织好的投资数据上下文就会形成了一个大任务,将这个大任务丢入到Fork/Join框架中,Fork/Join会自动按每个投资规则和投资数据上下文拆分成N个小任务并行运算生成抵销分录。
自定义独立的合并计算ForkJoinPool,避免影响JDK并行流工具的性能,便于监控跟踪。
采用Redis管理合并计算进度信息,提供进度监控支持。
四、合并计算使用Fork/Join后的性能
基于JMeter工具进行单节点应用性能压测,按照某大型建筑企业项目的实际业务组织机构(10000+),验证系统在填报期内,混合场景下合并计算的稳定性和并发处理能力,以及各业务功能执行效率。在CentOS7操作系统、8核CPU、32GB内存环境下,模拟100人合并计算,持续10分钟压测,事务通过率在性能指标要求范围内,CPU、内存、磁盘、网络等资源消耗均符合要求,无异常,平均每20秒左右完成一次合并计算操作,测试过程中没有出现FullGC情况,满足项目实际场景。
以上主要介绍了Fork/Join框架的基本原理,核心的分而治之、工作窃取能力,以及在合并报表合并计算场景中的应用。
久其新一代合并报表经过基础计算架构的提升,有效的增强了合并计算大任务拆分成小任务的分治能力,实时合并计算变得更加精准、高效,为集团合并“一键出表”打下了更加坚实的基础。
久其新一代合并报表基于久其女娲平台开发,女娲平台是一个以开源技术为基础的新开发框架,包含了一系列公共服务或组件、一套标准化的参考构建流程和相应的配套设施、一套开发模块化的开发规范,是集成了研发流程、工程规范、应用架构的良好实践的软件能力平台和工作空间。

